針鋒相對,卡王對決GTX 680 PK HD 7970

今年的上半年度由於新一代顯示卡、處理器和主機板的推出,讓整個IT業都熱鬧了起來!玩家們滿心歡喜期待,而編輯們也沒閒著,不斷忙著測試和寫稿,即使加班熬夜也要完成報導,讓讀者們都能輕鬆掌握新產品的資訊!
小編這幾個月可忙得很,不久前AMD才推出HD 7000系列,近日NVIDIAGTX 600系列也由GTX 680揭開序幕,所以每個月都有要把玩數張顯示卡。但是最為重要的不外乎就是一年一度的卡王對決,由AMD HD 7970對上NVIDIA GTX 680,這兩張都是單晶片最高階的旗艦產品,不論是設計、功能或是價格,都有很多地方值得大家一起來討論,接下來就讓我們一起來討論這兩張旗艦產品吧!
█ 前言
還記得去年再163期本刊的封面故事GTX 580和HD 6970的對決嗎?已經不記得的同學們還不去翻一下!好吧,很顯然各位已經拿去墊桌腳,或是只有吃泡麵才會拿出來。其實常摸顯示卡的玩家應該都明白,去年GTX 580和HD 6970這兩張卡雖然受單晶片最高階,但是定位卻不太一樣,GTX 580整體效能遠勝HD 6970,就連價格也相差約5000元新台幣!我們先不論為什麼落差這麼大,但是已經等級來說,這兩張卡都是NVIDIA和AMD最高階的產品,即使明知道效能上有落差,依照先例旗艦對決是免不了的!
轉眼間一年時光又匆匆消逝了,隨著28奈米新製程技術突破,最新的HD 7970與GTX 680都相繼在2011年12月和2012年3問世,這一次兩家的產品只相隔約3個月,是近年來推出時間相差較近的一代,且不論硬體設計或是價格都是旗鼓相當,尤其是這一代的產品由於製程進步的關係,增加了許多新技術與功能,例如AMD的GCN架構(Graphic Core Next)、ZeroCore Power,NVIDA則是有SMX架構、GPU Boost、Adaptive Vsync等全新功能,但是兩家新產品還是有支援相同的功能,就是PCI-E 3.0和DirectX 11.1兩大重點技術,後面小編會更詳細說明上述的功能與技術。


圖 / 兩大品牌旗艦產品外觀樣式,與上一代相比質感略微提升。
從規格表來看,這兩款顯示卡相較於上一代都有很大的提升,尤其是GTX 680更是顯著,由於利用製程進步的優勢,在核心體積不變的條件下,一舉將CUDA核心數量從512個提升至1536個,是原先的三倍之譜,時脈也大幅提升了23%左右,而記憶體只增加512MB,在多數規格都提升的情況下,記憶體位元寬卻從384-bit減少為256-bit,相信許多玩家都會覺得匪夷所思!此外,GTX 680的外接電源只需要6Pin×2,對於近幾代的顯示卡來說非常特別,難道GTX 680還不算是高階卡嗎?以上這些問題在下個階段小編都會一併為各位解答。
再來看到HD 7970的規格表,大致上較為明顯提升的部分為核心數量、時脈與記憶體規格,核心數量增加了512個,但以提升比例來看還是NVIDIA取勝。時脈其實提升45MHz其實並不明顯,通常各品牌出貨版的超頻幅度都不只45MHz,或許是有所保留,讓各品牌推出時能有更大的超頻空間;記憶體的部分早期一直都是AMD顯示卡的優勢,當NVIDIA還在使用GDDR3時,AMD就推出業界第一張使用GDDR5記憶體的顯示卡,而且時脈遠比NVIDIA顯示卡高出許多,可以比對一下GTX 580和HD 6970的記憶體時脈就知道。唯獨讓小編讚賞看好的是,記憶體的位元寬終於從原本的256-bit提升至384-bit,因此頻寬也加大了,傳輸速度提升對於運算效能有一定的幫助!
|
NVIDIA規格表 |
||
|
詳細規格 / 產品名稱 |
GTX 580 |
GTX 680 |
|
核心數量 |
512 |
1536 |
|
核心時脈 |
772MHz |
1006MHz(OC 1058MHz) |
|
記憶體時脈 |
2004MHz(4008MHz) |
1506MHz(6000MHz) |
|
記憶體容量 |
1536MB GDDR5 |
2048MB GDDR5 |
|
記憶體位元寬 |
384-bit |
256-bit |
|
記憶體頻寬 |
192.4GB/s |
192.2GB/s |
|
最高功耗 |
244W |
195W |
|
外接電源 |
||
|
AMD規格表 |
||
|
詳細規格 / 產品名稱 |
HD6970 |
HD7970 |
|
核心數量 |
1536 |
2048 |
|
核心時脈 |
880MHz |
925MHz |
|
記憶體時脈 |
1375MHz(5500MHz) |
1375MHz(5500MHz) |
|
記憶體容量 |
2048MB GDDR5 |
3072MB GDDR5 |
|
記憶體位元寬 |
256bit |
384-bit |
|
記憶體頻寬 |
176GB/s |
264GB/s |
|
最高功耗 |
250W |
250W |
|
外接電源 |
8Pin+6Pin |
8Pin+6Pin |


圖 / HD 7970內用用料一覽,供電模組為5+2相。


圖 / GTX 680內部用料一覽,供電模組為4+2相,相較上一代減少許多。
█ 通用運算迫使AMD更改架構
小編相信現在有多數人都還在使用N年前的產品,沒辦法,顯示卡技術就是發展得那麼快,短短幾年間從1XX奈米到今日已經進步到28奈米,光是相較於上一代的40奈米就有很大的差異性,所以接下來要進入核心架構的比較,才能知道這一代究竟是改進了那些。
顯示卡在互相較勁時,通常都會從核心的架構開始,核心的設計是影響效能的重要因素,尤其是這一代兩大品牌都推出新款的28奈米產品,整個核心內部架構大翻修,雖然從架構圖看起來差異並不大,但其實可以說幾乎都快翻新了!先看到AMD推出的Tahiti XT繪圖核心,首次採用了Graphic Core Next架構,在架構圖中標示了許多GCN,這就是這次HD 7970所使用的GCN核心架構,是AMD多年來首次深度更換核心架構,而原先以前SIMD陣列的位置,取得代之的是GCN陣列。不曉得各位知不知道其實AMD在GPGPU的部分效率並不如NVIDIA來得好,由於當時NVIDIA推出Fermi架構時,大幅提升GPGPU的運算效率,因此才會看到從GTX 400系列開始大力強調轉檔和硬體加速等相關通用運算,簡單來說,以往顯示卡能只用於圖形運算,近年來已經可以兼具通用運算的能力。
註:GPGPU的全名是General-Purpose Computing on Graphics Processing Units,就是所謂的通用繪圖處理器。
█ VLIW4瓶頸迫在眉睫,GCN解套!
提升通用運算就能擴展顯示卡的領域,或許就是這種動力促使AMD更改核心架構!在發佈GCN架構的同時,AMD也強調「圖形就是計算,計算就是圖形」的理念,很明顯AMD不想讓NVIDIA專美於前。會大幅更改架構的另一個因素,就是舊有的VLIW5(HD 5970以前)與VLIW4(HD 6970)執行的效能不彰,不過為何效率不彰呢?我們以較新的VLIW4來舉例,採用4D架構,簡單來說GCN架構的前身SIMD,就是由4個1D向量為一組(向量由多個純量所組成),並且可同時平行運算,但是,當只需要由1D的純量來運算時,那麼其餘的處理單元都幫不上忙,如此一來效率自然就降低了!加上從VLIW5改成VLIW4之後,由於電晶體數量大增,雖然效能較優異,但功耗也隨之提升,所以說如果再不更改架構,那下一代的功耗將會非常可觀!
新架構的GCN和舊架構VLIW的處理效率以天地之差來形容一點都不為過,最主要的差異是VLIW為指令平行,而GCN則是執行續平行,運算程序大不同!GCN架構中主要有32組的CU(Compute Unit)計算單元陣列,而每一組CU內包含著4個SIMD模組,每個模組內更是有16個ALU處理單元,拿台計算機算一算總數有2048個ALU,就是我們常說的流處理器,相較於HD 6970,流處理器的數量足足多出了512個,也因此大幅提升運算能力。事實上一開始AMD公佈GCN架構時,早就說明GCN是一個以SIMD為基礎的MIMD架構,不過當時外傳AMD有40組CU的HD 7970,雖然未被證實且良率也讓人質疑,但從GTX 480的前例來看,起初良率不高而隱蔽8組CU也是不無可能!
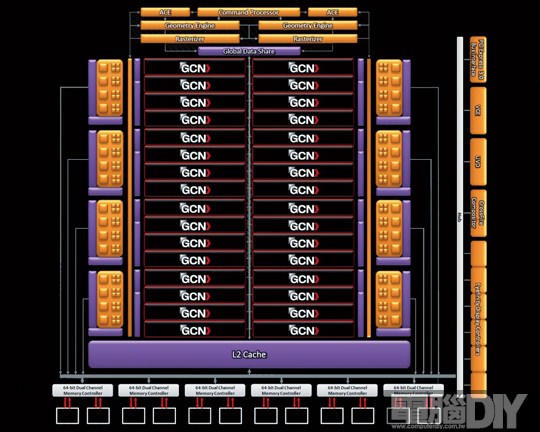
圖 / 全新的GCN架構,除了增加512處理單元,也大幅度增進CU單元的處理程序,
運算效率上遠超過上一代。
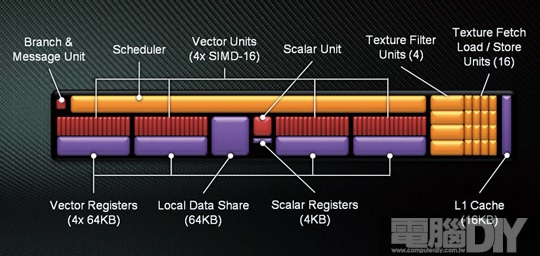
圖 / CU單元的架構圖中,可明顯看出有4組16個ALU處理單元。
█ NVIDIA祭出Kepler出戰GCN
前面提到或許是因為Fermi的關係,讓AMD感受到強烈的威脅,我們不得而知,但有一點可以確認的是,Fermi在GPGPU的部分效率相當高,這是因為自從NVIDIA提出CUDA概念之後,將處理單元個別拆開,每一個CUDA核心都是單兵,需要多少人力來做多少事都能詳盡分配,不會浪費核心資源,當然會比VLIW架構更有效率。GTX 680所使用的新架構名為Kepler,但是從核心架構圖來看,不難看出依舊保有Fermi的基本架構,只是規模似乎有點不太一樣?眼尖的讀者應該早就看出GTX 680的CUDA核心數量遠多過於GTX 580,算不出有多少吧!GTX 580有512個CUDA核心,而GTX 680卻足足有1536個CUDA核心,數量達三倍之譜!
Kepler主要的重點就在這4組的GPC處理器模組,GPC模組的設計是從GF100核心開始(在這之前稱為TPC),在沒有更先進的設計之前,GPC模組將會是NVIDIA核心設計的主要架構。從圖中可以看到每一組GPC處理器主要包含2組的「SMX模組」,所以可以將GTX 680想像成八核心處理器的GPU!在以往的核心架構中,這部分稱為SM「Streaming Multiprocessor」流處理器模組,但新架構已改為SMX「Streaming Multiprocessor Extreme」極致流處理器,在這每一組的SMX中擁有192個CUDA核心(GF110只有32個),因此總數才會是1536個。在上一期小編GTX 680的介紹中,小編已經詳細解說GTX 680核心的運算程序,以下就簡單再描述。
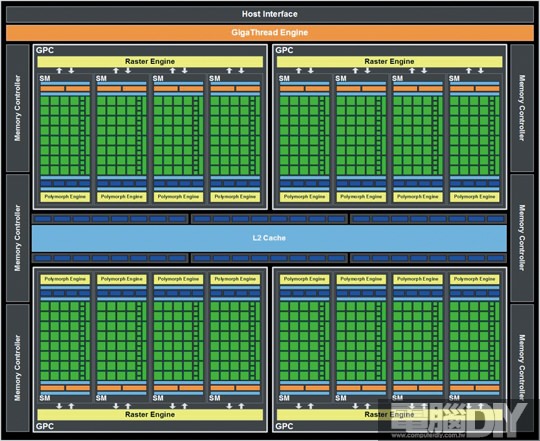
圖 / GTX 580所使用的Fermi二代GF110核心架構
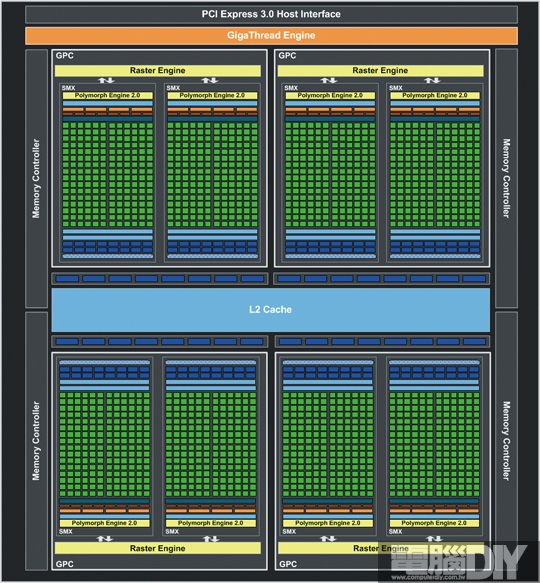
圖 / 新架構Kepler明顯是減少SM陣列,並大幅增加CUDA核心數量。
█ Kepler:速度才是王道!
或許對AMD來說,GCN架構的創新設計能大幅提升運算速度,但相較於NVIDIA來說,除了保有原來通用計算的優勢之外,減少GPC模組但大幅增加處理單元,最明顯的就是效率上的提升。如果我們深入SMX中來看,就會發現SMX模組和SM一樣有CUDA核心與各種計算單元,內建4個Wrap Scheduler調度器和8個Dispatch Unit指令分配單元,Wrap Scheduler是用來調度SMX內的所有CUDA核心以及SFU單元,因此在上一段中有提到處理圖像時,GigaThread引擎會下達指令給SMX,再經由SMX內的Wrap Scheduler將工作分配給CUDA核心,所以我們將它簡單化之後,GigaThread引擎就像是指揮官一樣,而Wrap Scheduler如同是隊長,指揮CUDA小隊執行任務,有多少工作就使用多少CUDA核心,這樣是非常有工作效率的做法!
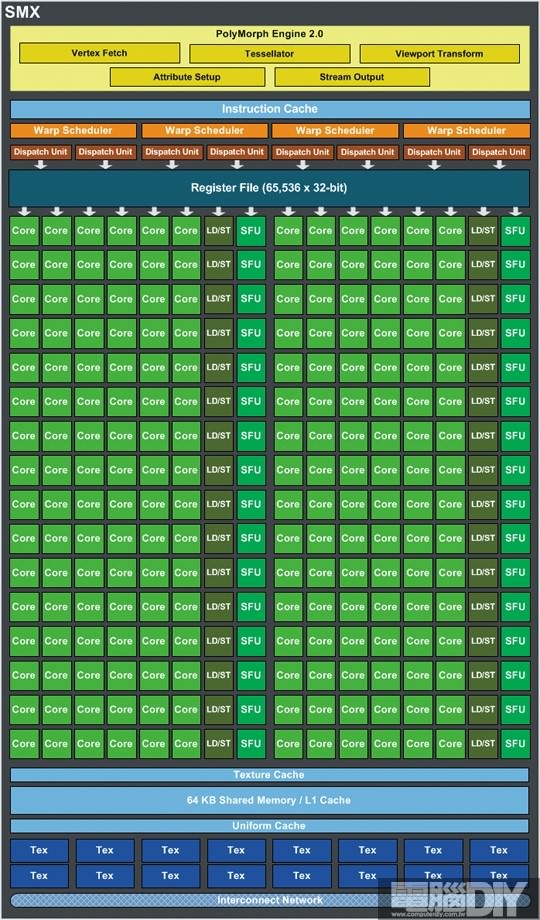
圖 / SMX細部架構圖,可以看到各個處理單元都是以往的數倍之多。
█ 記憶體控制器的改變
除了核心之外,這次要提一下記憶體的部分,由於遊戲的運算需求越來越大,所以除了核心的運算速度之外,HD 7970和GTX 680的記憶體都有做改變;相較於HD 6970,HD 7970的記憶體增加到6個64-bit記憶體控制器所組成,所以位元寬從原先的256-bit提升至384-bit,但記憶體顆粒的工作時脈並沒有提升,最高還是和HD 6970一樣為5500MHz,記憶體高時脈一直以來都是AMD顯示卡的優勢,相反的早期NVIDIA在記憶體控制器的設計還有很大的進步空間,因此運作的時脈遲遲無法突破。
反觀NVIDIA這次在GTX 680上使用全新設計的記憶體控制器,但是數量從GTX 580的6個減為4個,所以位元寬就只有256-bit,不過全拜新設計的記憶體控制器所賜,GTX 680的記憶體時脈一舉突破6000MHz,相較於GTX 568提升了約2000MHz,打破有史以來顯示卡記憶體時脈最高的紀錄,即使控制器只有4組,相信也能夠透過高時脈來彌補頻寬的不足!
█ 新技術帶來全新功能
每當新款顯示卡推出就會帶來不同的驚喜,HD 7970和GTX 680也分別帶來不同的新功能給玩家,這兩家的產品多年來的訴求都不一樣,不過這一代還是有同時都有支援的功能,比方說PCI-E 3.0和DirectX 11.1,這先前小編都介紹過了,老實說目前玩家們都還沒辦法體會到這兩大功能,尤其是PCI-E 3.0,雖然Z77和X79平台都有支援,但在一般遊戲的需求下根本塞不滿這麼大的頻寬,因此現階段只能說有支援但用不到。支援DirectX 11.1也是為未來Windows 8所準備的遊戲特效技術,就像當年DirectX 10更新到DirectX 10.1一樣,這部分屆時會再另外介紹。
以AMD的技術來說,這兩年極力推動Eyefinity多螢幕功能,但是由於三螢幕所需要的效能加倍,想要順暢的遊戲畫面就必須要使用中高階以上或是雙顯卡,而且多螢幕對多數玩家來說並不是絕對需求,因此AMD在消費端推廣上有難度。如今推出Eyefinity 2.0,雖然顯卡效能提升不少,並且對多螢幕輸出也有優化,甚至原本就不太推廣多螢幕的NVIDIA,竟已經在GTX 680上提供單卡四螢幕的功能。老實說並不是小編不看好,而是目前的螢幕技術來無法達到薄邊框甚至無邊框,使用多螢幕玩遊戲有時候會造成視角盲點,在還沒有適當的螢幕之前,這項技術將只會是附加功能,有也未必用得到。

圖 / HD 7970支援Eyefinity 2.0,畫質更提升,效能更優異!

圖 / NDVIDIA首次在GTX 680上支援單卡四螢幕
█ 創新的GPU Boost智慧超頻技術
想必多數玩家都知道CPU會自動超頻,依照不同負載調整時脈的高低。而GPU以往在低負載的情況下會降低時脈運作,但負載增加並不會提升時脈,這部分在GTX 680中已經找到答案了!透過專用的控制IC隨時監控GPU的運作狀態,GTX 680核心的基本時脈為1006MHz,當GPU負載達到TDP的上限時會即刻啟動GPU Boost功能,並將時脈提升至1058MHz以上。但這並不是固定值,小編測試手上的GTX 680,進行遊戲時所測得的時脈為1097MHz,且原廠的說法,在某些情況下會甚至超過1100GHz以上!而原廠也表示目前GPU Boost是無法自行關閉,但這方面NVIDIA未來會提供API給合作夥伴,讓各品牌都能推出GPU Boost相關的控制軟體,讓玩家們也能自行調校。AMD目前並沒有相關的技術,但這次的一部分測試也會將HD 7970時脈調整與GTX 680一樣給玩家們參考。
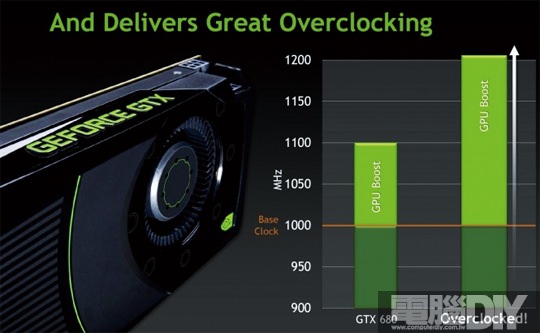
圖 / GPU Boost是一相顯示卡創新的功能,會依照負載量進行超頻。
GTX 680還有個Adaptive Vsync的技術,和我們所知道的垂直同步相去不遠,唯獨不同的地方是垂直同步需要手動開啟,但是Adaptive Vsync會自行偵測畫面FPS,當大於螢幕更新率時會自動開啟Adaptive Vsync功能,確保畫面不會出現撕裂狀態;一但FPS過低,Adaptive Vsync將會自動關閉,維持畫面的流暢度!
█ 遊戲效能測試
接下來就是真正進入PK賽,也是最現實的時刻!這次測試的項目依然是各種熱門遊戲,分別有3DMark 11、DirectX 10、DirectX 11,和針對Tessellation項目的Haeven DX11 Benchmark v3.0,最後則是有基本的運作功耗的測試。以下的測試成績會因為測試環境和其他硬體所影響,所以成績的部分僅供玩家參考,因為小編所提供的測試成績為多次的平均值,部分成績有些微差距都可能是誤差值,接下來就是測試的部分。

圖 / 兩張新款顯卡對於Tessellation運算都大有進步,尤其是HD 7970進步幅度極為可觀!
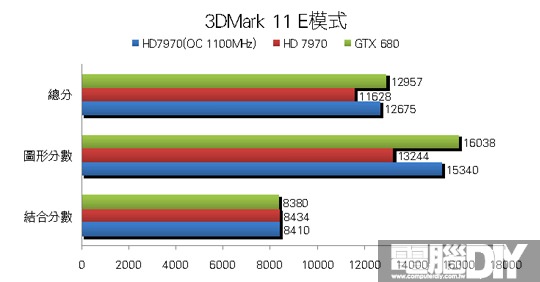
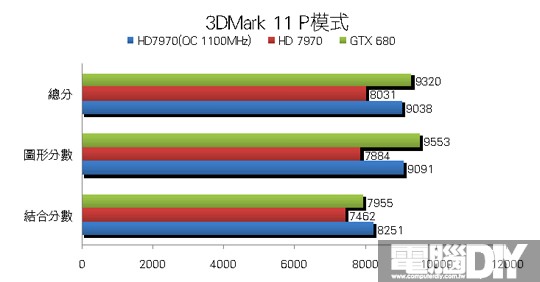
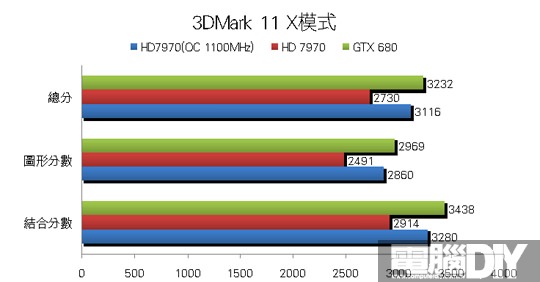
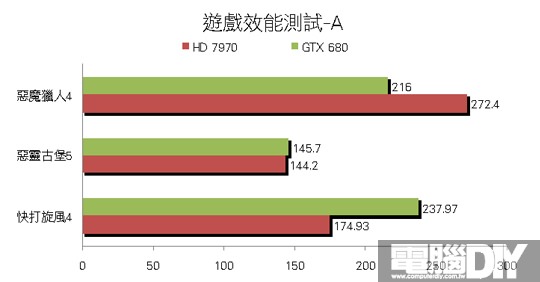
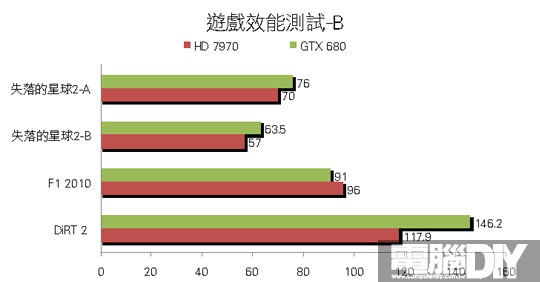
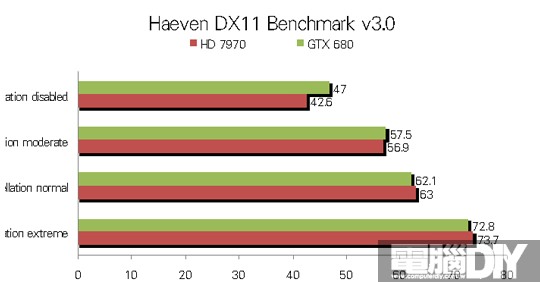
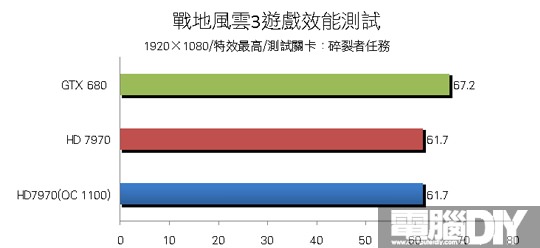
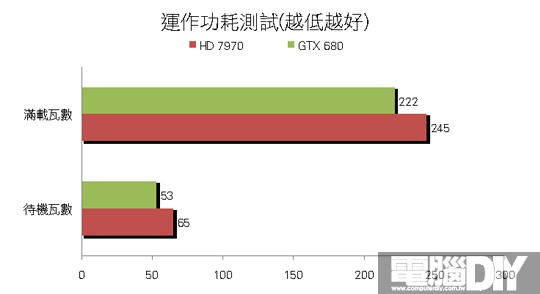
█ 結論:勢均力敵
從以上的測試成績來看,很明顯這兩張顯示卡相較上一代效能提升非常多,處理單元的大幅增加和記憶體的效能提升,都是提升遊戲效能的主要因素。除了許多新功能之外,由於28奈米製程的因素,讓整體功耗都大幅降低,一般高階卡都需要8Pin+6Pin的外接電源,但是GTX 680卻能夠做到使用雙6Pin就好,官方公佈的TDP也只要195W,可見這次NVIDIA在供電的部分令人讚賞!HD 7970也推出ZeroCore Power技術,在多顯卡待機的環境下關閉第2張以後的顯示卡,讓電源最低只有3W~5W左右,休眠時幾乎是不使用電源,但是單卡本身卻達到近250W,這方面似乎還有進步空間!


圖 / 圖上為GTX 680,外接電源只需要雙6Pin,右下的HD 7970比照以往高階卡8Pin+6Pin供電。
其實除了3DMark 11有較大差距之外,其餘遊戲的部分可說是平分秋色,多數遊戲的差距都相當小,很明顯可以看到這兩款顯示卡在那些遊戲中較有優勢,雖然GTX 680有GPU Boost功能,但是小邊疆HD 7970的時脈調到與GTX 680一樣時,最後得到的成績其實相當接近,如果再進一步提升時脈肯定大有作為。最後小編認為AMD這次確實有非常大的進步,大改架構後處理效率大幅提升,效率提升相對也會更省電,搭配眾多先進功能之後,相信這一代的顯示卡能在市場上大放異彩!
臉書留言