Intel Skylake Z170硬派實測, 傳輸全方位 內顯進化論

今年夏天,先是有Window發佈新一代視窗作業系統,緊接著千呼萬喚始出來的Skylake / Z170平臺也隨之橫空出世,對於想要換電腦的朋友來說,軟體與硬體都可以一次到位。以現行消費端需求來看,處理器的浮點運算效能已經達到一個相當不錯的水準,在文書用途下,不需要Core i7 / i5出馬,請出Core i3甚至Pentium家族就能滿足日常需求。
反倒是在顯示效能部份,隨著遊戲效能需求與4K解析度日益普及,DIY玩家大多會加裝一張獨立顯示卡使得平臺戰力更加完整;此外,讓人眼花撩亂的各式儲存裝置,也讓傳輸瓶頸的問題浮上檯面,我們在這次Skylake / Z170平臺測試上,不難發現Intel即針對了內顯iGPU與PCIe Lans數量的提昇上,正面回應了使用者的心聲。而Skylake / Z170有什麼新的亮點?就來看看胖達這期的測試報導吧!
Intel Tick-Tock戰略
自從2006年Intel不再和A社比拼時脈,跳脫Netburst微架構包袱之後,Core微架構搭配「Tick-Tock」策略之後,I社稱霸x86處理器迄今,甚至在移動運算市場也有所斬獲;同時,處理器的進步週期亦有了脈絡可循。所謂的Tick-Tock,則是英特爾研發處理器時,所發展出的一種戰略模式。簡單來說,每一次處理器微架構的更新,以及每一次晶片製程的改進,兩者之間的時間點應予以獨立、錯開,如此一來,則會有更加良性地發展。
顧名思義,就像鐘擺裡的「Tick」與「Tock」,每一次Tick,代表著新一代的製程更新,意即處理器在效能相距不遠的情形下,縮小晶片面積,便能降低功耗與溫度;而每一次Tock,則意謂著在上一次Tick製程基礎上,將處理器架構予以更新,實現效能方面的提升。按照英特爾Tick-Tock策略,本次Skylake架構係屬於Tock階段,研發主要由隸屬於英特爾的以色列海法團隊負責;主要用以取代Haswell與Broadwell微架構。
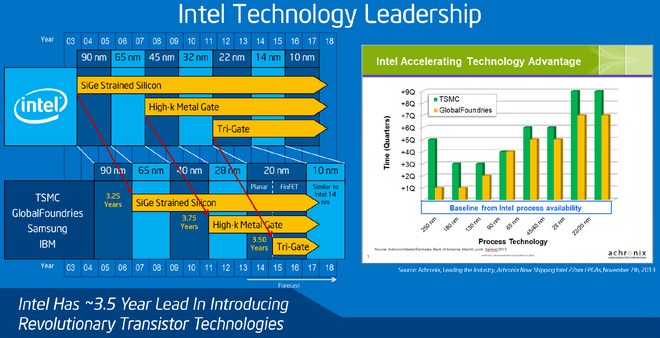
↑ 近10年來,英特爾由90奈米到今天Skylake的14奈米,效能成長顯著。一路走來,Tick-Tock戰略功不可沒。
六代目Core微架構
本次發佈的Skylake是第六代Core i處理器,我們也順便為讀者們複習一下Core架構處理器的特性。相較於A社處理器與自家先代Prescott核心,Core架構管線深被大幅縮減,相較之下,管線越深,越容易將時脈拉高,但若分支預測失敗或是快取不中時,其所衍生的延遲時間就越長,以Prescott來看,共有31級管線,一旦預測失敗或快取不中,就會招致31個週期的延遲,此時只有14級管線深的Core核心的優勢就相對顯而易見。
除此之外,Core微架構在分支預測單元也有所進化,除了延用分支目標緩衝(Branch Target Buffer, BTB)、分支地址運算(Branch Address Calculator, BAC)以及堆疊返回(Return Address Stack,RAS)之外,Core微架構還導入了迴圈偵測器(Loop Detector, LD)及間接分支預測單元(Indirect Branch Predictor,IBP)這兩種嶄新的預測單元。前者可以高效率預測迴圈的結束,而後者則可以透過全局資料進行更加精準的預測。透過這樣的設計,預測更加精準,避免落於預測失敗或快取不中的低效率延遲。
除此之外,先前的微架構設計在分支轉移時,必然會浪費一個管線週期的延遲,而Core微架構則在分支預測單元與快取單元中增加一個陣列,大幅降低這個週期被浪費的必然性。
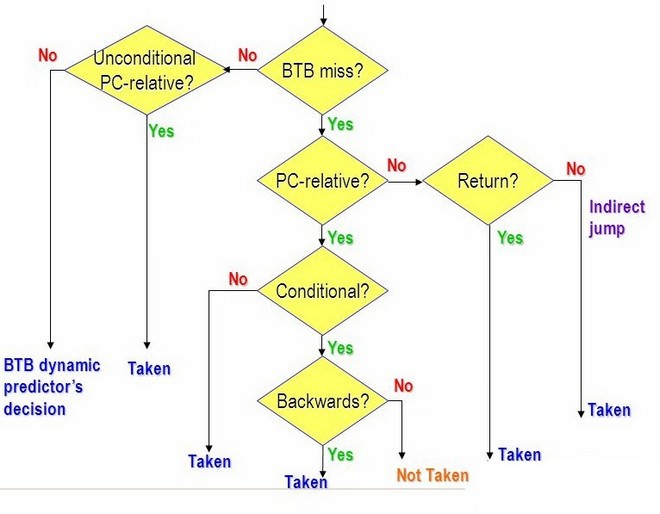
↑ Core微架構在分支預測單元也有所進化,除了延用BTB、BAC以及RAS之外,Core微架構還導入了迴圈偵測器及間接分支預測單元,使得運算效率得到大幅提昇。
效率更好、功耗更低
Core微架構另一個進化點,在於採用了四組指令編譯器,主要由三組簡單解碼單元及一組複雜解碼單元所組成。同時,Core微架構使用了微指融合技術,在微指令減少的情況下,相同的單位時間內處理更多指令,反應在實際面上,就是運算效能的直接提昇。而且別忘了,微指令減少的另一個好處,就是處理器功耗的下降。
而大容量快享式L2快取,同時降低了存取延遲之外,也拉高了快取利用率,甚至某些狀況下,單個核心也可以完全使用4MB快取,而L1 / L2快取的匯流寬都是256-bit,使得I/O能力得到了飛躍式的提昇。
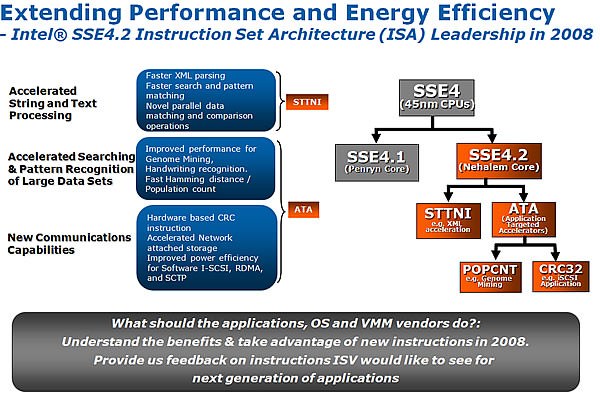
↑ Core微架構發展至Nehalem核心之後,在SSE 4.1 指令集基礎上,新增了 7 組 SSE 4.2 指令。除了鞏固原有多媒體圖形處理 / 顯示與編碼之外,也將字串與文本處理指令相關應用,一併強化後整合於處理器之中。例如 ︰XML 應用進行高速查找及對比,對伺服器領域來說相當實用。
不硬拼時脈 切A社中路
預先加載機制,也是Core微架構的一大特色,透過歷史資料依存性預測功能,得處理器將資料回存到儲存單元的同時,一同進行資料預先抓取動作,讓某些需要的資料,先放在記憶體中,讓快取存取次數得以降低,那麼大容量記憶體的利用率可以發揮得更加充份,而珍貴的快取因為存取次數降低,因此延遲得以大幅下降。
最後,Core微架構搭載智慧電力管理功能(Intelligent Power Capability),簡單來說,該功能使得處理器內各功能單元不再保持隨時啟用狀態,而是透過預測機制,啟動會用到的單元。透過嶄新的分離式匯流槽設計(Split Buses)、數位化熱感應偵測器(Digital Thermal Sensor)及環境平臺控制介面(Platform Environment Control Interface)等技術,使得功耗得到大幅度的下降。也因此,反映在第六代Skylake處理器上,依然保持著低功耗、高效率而不一昧追求高時脈的特性。
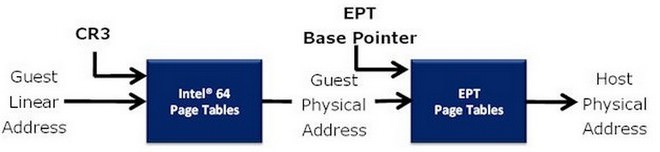
↑ Core微架構Nehalem核心針對虛擬化(Virtualization)也作出了相當大的改善,像是減少虛擬主機的進出次數,降低轉換延遲及加入擴展頁表( EPT ),能夠最佳化記憶體在虛擬化系統的表現,將多核心的優勢完全予以發揮。
晶片組 全都露
綜觀上述所敘,自英特爾第一代酷睿處理器發佈以來,與美商超微(AMD)之間的效能競賽,已逐漸拉開了差距。到了Ivy Bridge及Haswell處理器,在製作工藝上,同以22奈米製程,搭配三柵極電晶體(Tri-Gate)技術而成。
新一代Skylake採用1151腳位,與前代Haswell所使用的1150腳位有所不同,因此主機板自然無法延用。按照慣例,本次英特爾與多家主機板廠,首波推出了Z170晶片組產品,用以取代前代Z97效能級(Performance)定位;緊接而來,則是以H170取代Z97主流級(Mainstream)定位,最終才會發佈H110,取代H81入門款(Basic)定位。
按照Intel的兼容政策,理論上LGA 1151插槽,將沿用至更下一代的Cannonlake處理器上,如同Z87/Z97相容Haswell / Broadwell處理器一樣。
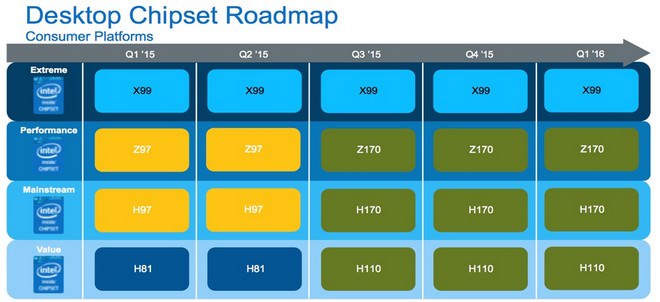
↑ 在 100 系列晶片組產品線中,將會提供 6 款產品,其中家用端 H110、H170、Z170,也是DIY領域的主力產品。
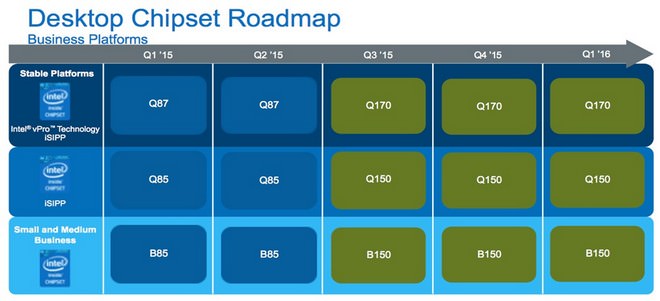
↑ Q170、Q150、B150定位為商用端所用,在一些套裝電腦上很容易便能發現。
SATA 6Gbps / USB 3.0 全線搭載
基本上,Z170晶片組作為效能級定位,相對H170、H110而言,除了支援2×8或1×8+2×4多路顯卡SLI/CrossFire之外,全系列搭載SATA 6Gbps及USB 3.0高速I/O介面。此外,Z170相對H170、H110在SATA、USB傳輸埠的數量上較多;而H110相較H170則少了ISRT及RAID功能,同時H170也不會搭載SATA EXPRESS介面。
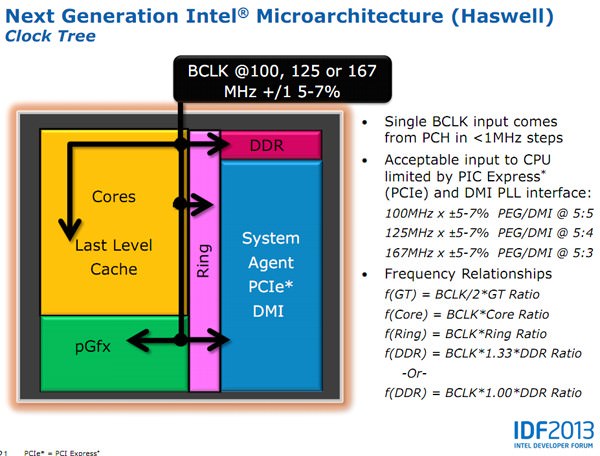
↑ 在IDF 2013中,英特爾詳細揭露了BCLK與其他模組元件的頻率關係式。若想輕鬆玩超頻的讀者,不妨先弄清楚其間的映射關係。舉例來看,圖中f(GT)= [BCLK/2]*GT Ratio,這個函式直接告訴你︰內顯頻率,等於BCLK基頻的一半。
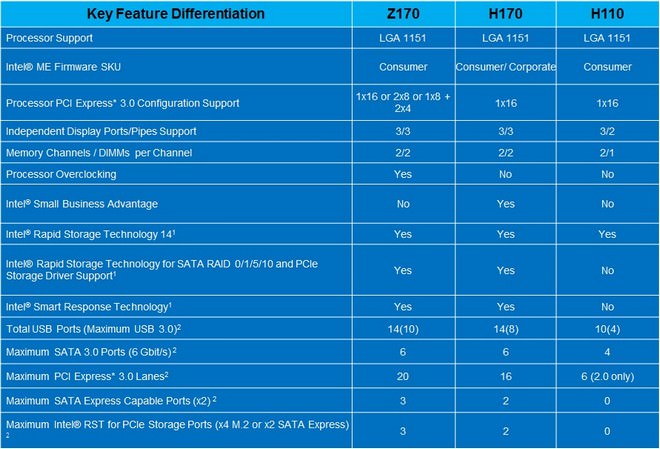
↑ Z170將在本月發佈,接下來H170、B150及H110預計將於九月發佈,由本表格可比較出三者的功能差異。
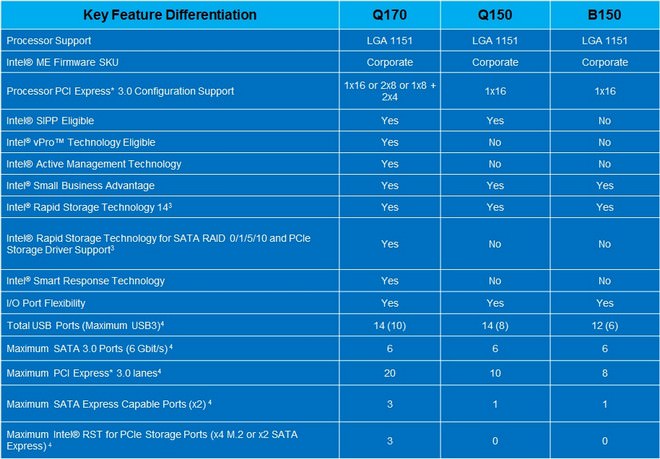
↑ B150晶片組雖然預計於九月發佈,但Q170、Q150晶片組預計將到第三季才發佈,由本表格可比較出三者的功能差異。。

↑ 新一代Z170主機板,搭載LGA 1151腳位插槽,仍可沿用到更下一代Cannonlake處理器之上。
混合硬碟 動態加速
許多朋友分不清楚I.R.S.T.(Intel Rapid Storage Technology)與I.S.R.T.(Intel Smart Response Technology)的區別,在100系列晶片組產品中依然搭載,胖達趁這次機會順便予以解釋。前者是INTEL的AHCI/RAID驅動程式,而後者則是建構在前者下的功能之一。換言之,只要在AHCI或RAID環境下,都可以安裝I.R.S.T.,而又因為XP並無內建AHCI驅動程式,因此在XP環境下建議安裝I.R.S.T.;當然,到了Windows 7以後就沒有這個問題了。此外,建議大家可以把UEFI BIOS裡面PCH原生SATA埠的熱插拔功能予以啟用,如此一來,某些裝置在LPM(Link Power Management)模式才能溝通,不會發生意料之外的狀況。
另一方面,I.S.R.T.是所謂的智慧反應技術「智慧反應技術」(Intel Smart Response Technology,ISRT),在Z87晶片組之後該功能再改版成「動態硬碟加速技術」(Dynamic Storage Accelerator)。透過該技術,玩家可以將SSD拿來當作機械式硬碟的快取。當用戶面臨預算有限,卻又捨不得SSD的極緻效能時,便可以透過價格低廉的小容量SSD,製造出一顆虛擬式混合式硬碟,安裝之後隨插即用,無痛享受SSD所帶來的效能快感。相較前一代I.S.R.T.,新一代技術依照硬碟讀寫負載及供電策略加以動態調節,極大化混合後的I/O效能。
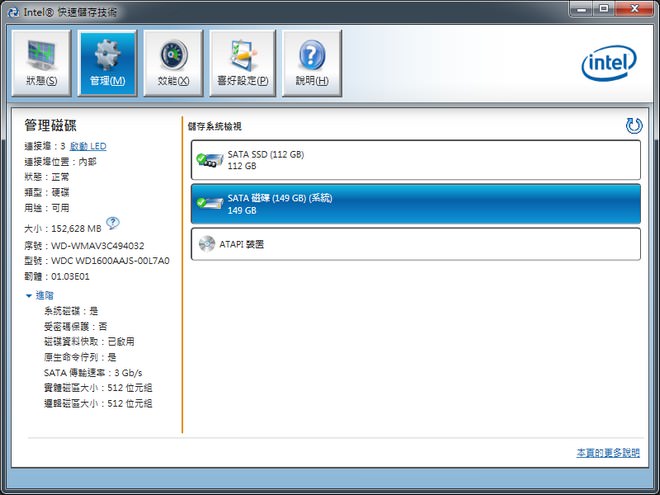
↑ 首先,在UEFI BIOS中,設定為RAID模式後。進入作業系統,點擊「管理」分頁選單,先確定系統裝設在機械式硬碟上;而SSD則為混合加速之用。
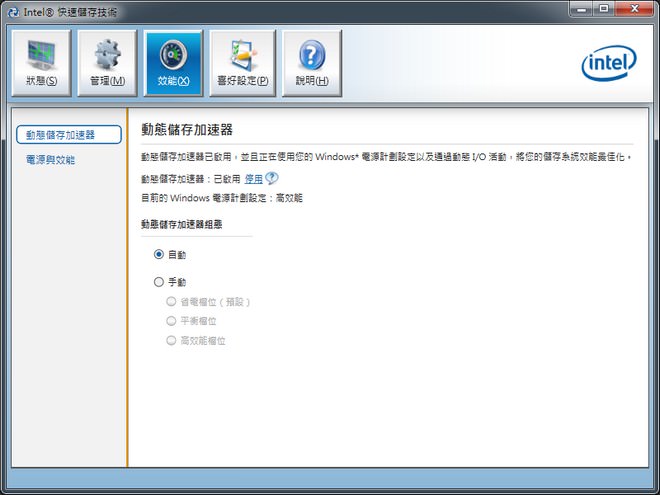
↑ 接下來,只要選擇「效能」分頁選單,接著點擊「動態硬碟加速技術」分頁,便可自動或手動建構混合式硬碟組態。
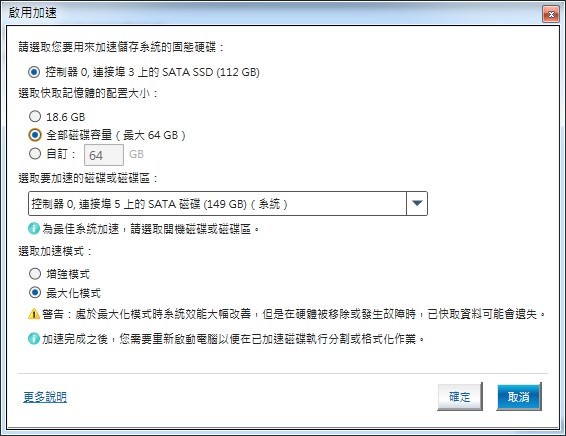
↑ 有「增強模式」及「最大化模式」可選,如果你已經習慣SSD的威力,建議你還是選擇「最大化模式」來享受吧!
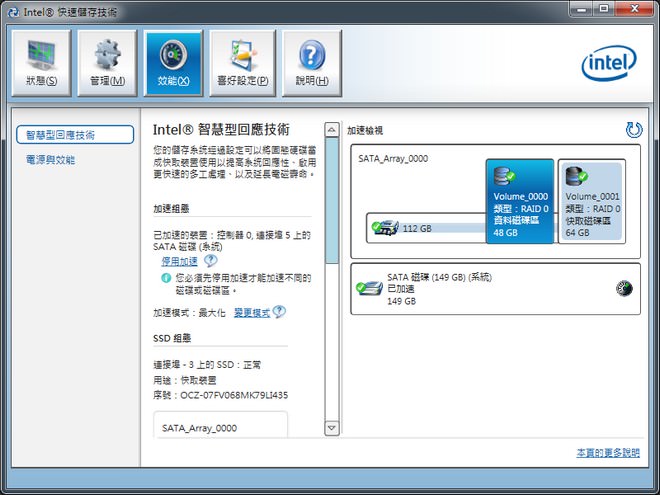
↑ 按下去後沒幾秒就完成,胖達的160GB藍標硬碟,也能享受接近SSD的極速快感!其實在7系列也有幾乎一樣的功能,只是設定較為複雜,令許多初學者望之卻步。
DMI 3.0 傳輸再進化
100系列晶片組將DMI通道頻寬予以強化,這對於儲存裝置來說可謂一大利多,但對於主機板的設計來看,如何分配PCIe Lans就成為了一項重大課題。我們以性能最強的Z170為例,扮演處理器與晶片組之間的溝通橋樑 DMI 3.0通道,其架構一舉由PCIe 2.0 x4 進化到 PCIe 3.0 x4,是以頻寬由雙向 4GB/s 躍昇為雙向 8GB/s。同時,原生PCIe Lans 3.0也一口氣來到了20條之多,相較於Z97僅原生8條可用,確實提供了更大的彈性。
我們在部份Z97主機板可看到不少較新的I/O介面,像是M.2、第三方SATA EXPRESS,由於通道數量的不足,因此許多I/O裝置的頻寬都是共用、介面都是共享,到了Skylake時代這樣的問題終於可以較為緩解。
在全新 Flexible I/O 架構下,100 系列晶片組Z170 與 Q170之 PCIe 通道最大數量為 20 條,其次H170共16條。而Q150 共 10 條、B150 僅 8 條、H110 只得最少的 6 條,基本上比起上一代9系列晶片組來得更多。同時,除了最低階的H110晶片組,其他100系列晶片組的PCIe介面都是3.0規格。

↑ 將主機板上的散熱片卸開之後,Z170晶片組真身嵌設其上。這次除了最低階的H110晶片組,其他100系列晶片組的PCIe介面都是3.0規格。
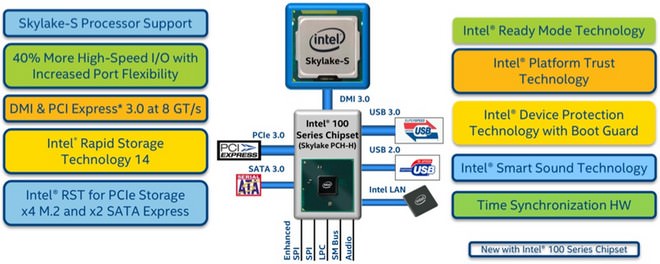
↑ 100系列晶片組概觀一覽,支援DMI 3.0 & PCIe 3.0 Lans,同時相容DDR4 / DDR3L,支援DX12、OpenGL 4.3/4.4及OpenCL 2.0繪圖技術,整體來還算頗具誠意。
Flexible I/O 變化更多 彈性更高
其實,Z170、H170、H110等晶片組的埠位,都是按照其定位,將晶片組原有的功能予以屏蔽及限制,如此一來,Flexible I/O在100系列晶片組由於數量更多,在架構上也就更為複雜。
從已經被公開的26埠(6埠USB通道、20埠PCIe通道)定義來看,第0埠~第10埠主要被作為USB 3.0通道使用,不過從圖來看,其中第7埠~第10埠,也可以拿來作為PCIe通道使用,甚至第10埠與第11埠還搭載了Port Physical Layer設計(PHY),能夠搭配GbE級網路晶片作為高速傳輸之用。
從架構圖來看,第10埠~第14埠主要作為PCIe通道使用,除了剛剛所說的第11埠搭載GbE級網路PHY設計之外,其他都是所謂的原生PCIe通道,無法挪作其他功能用途。
此外,值得一提的是作為USB 3.0通道的第1埠,尚支援OTG模式,因此標示為Dual-Mode;而第2埠~第3埠,還可作為SSIC(SuperSpeed USB Inter-Chip)之用,主要拿來作為晶片之間的運用,由於整合了USB協議層及M-PHY 實體層,因此具有功耗更低、傳輸效能不俗的特性。
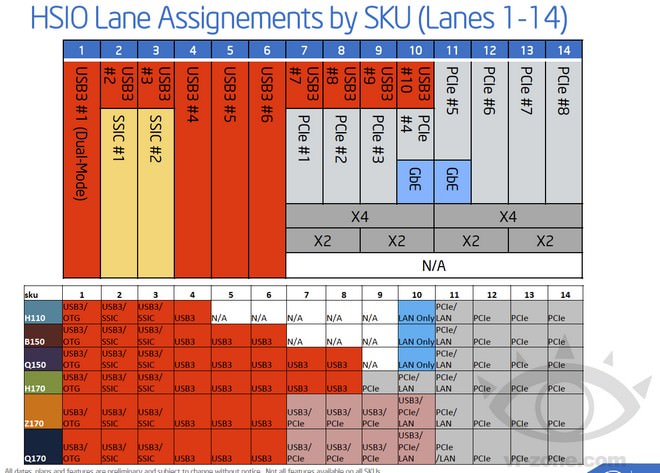
↑ 100系列晶片組,第1~14傳輸通道埠之架構定義。(圖片來源:VR-Zone)
左右相鄰 頻寬合併
接下來,第15埠~第26埠就顯得相對複雜許多,當中涵括了SATA、PHY、PCIe及IRST功能支援。由圖來看,第15、16埠及第19、20埠可透過PCIe Lans以Flexible I/O的方式作為SATA或是GbE PHY;而且,依照合併方式的不同,速度x2、x4都是可能出現的結果。
相較於前一段,我們討論的第7埠~第14埠並不支援IRST,而第15埠~第26埠則全部支援,換句話說,主機板廠若將第7埠~第14埠作為儲存裝置之用,像是定義為PCIe介面SSD之用得話,那麼在IRST介面中是無法看到這項裝置。
換句話說,非Flexible I/O的純粹PCIe通道,其實只有6+2條,由於想將PCIe Lans合併以拉高頻寬,需要兩兩相鄰方能實現,並不是任意抽兩個通訊埠就可以隨意合併。
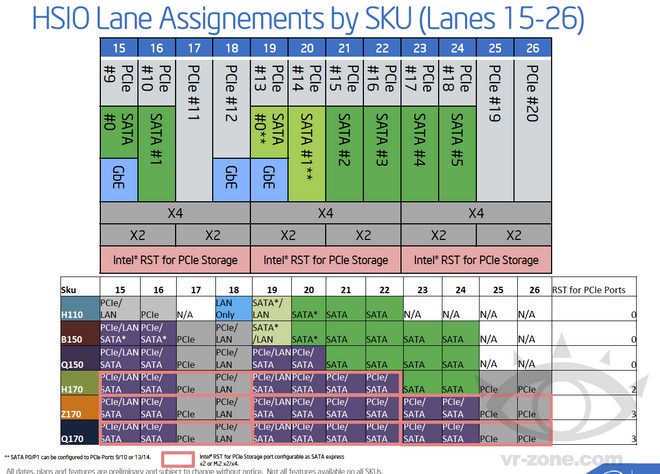
↑ 100系列晶片組,第15~26傳輸通道埠之架構定義。(圖片來源:VR-Zone)
彈性共用 取捨先決
從這26埠定義來看,帳面上雖然擁有高達20條PCIe 3.0 Lans、10個USB 3.0、6個SATA 6Gbps、3個SATA EXPRESS及3個M.2介面,但這些都是彈性共用的。實際上絕對獨立而無法被挪作他用的PCIe Lans只得8條、USB 3.0只有4個,而且沒有絕對獨立的SATA 6Gbps。這樣看來,如果主機板想要提供6個SATA介面而不透過第三方晶片,那麼頂多就只能有1個M.2,網路功能跟USB 3.0連接埠的數量也呈此消彼長的關係。如此一來,最佳化I/O就成為了主機板廠很重要的課題,以線性規劃的角度來看,網路晶片可以放在第10埠通道,而第7、8埠可透過PCIe方式導入USB 3.1晶片甚至Thunderbolt介面。第19~22埠則作為SATA 6Gbps及SATA Express雙工模式使用,第23~26則可合併成一個PCIe x4,那麼就有了一個超快的M.2 x4可用。此外,第15~18則可併為一個PCIe x4,其他像是第9埠及第11~14埠最簡單的作法就是直接當成PCIe x1介面種在主機板上,如果只需要一個PCIe x1,那麼第11~14埠就可發揮創意,透過第三方晶片實現該產品特色功能,像是若想實現傳輸速度高達40Gbps的Thunderbolt 3 (Alpine Ridge),那麼要合併的Lans就會需要更多。
所以我們算一算,以上述作法,Z170晶片組可輕鬆提供6個USB 3.0、2個USB 3.1、PCIe x1/x4插槽、SATA Express及M.2 x4介面。因為Z170原生就26埠通道可玩,所以像Z97主機板上常見的一轉多晶片在Z170上將不再會是常客。

↑ 100系列晶片組的PCIe 3.0 Lans夠多,因此技嘉這次就抓緊機會,導入最新一代Thunderbolt 3 (Alpine Ridge)介面,傳輸極速高達40Gbps,混合最新USB3.1,能夠令單一纜線輸出兩組4K影像能力,將100系列平台效能完全釋放。
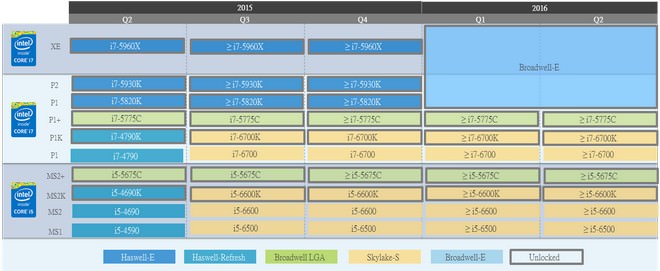
↑ 今年八月至九月間英代爾將發表第六代Core i5/i7 K型號處理器 (i7-6700k, i5-6600k),而Core i3、PENTIUM、CELERON 將於2015第四季至2016第二季陸續發佈。
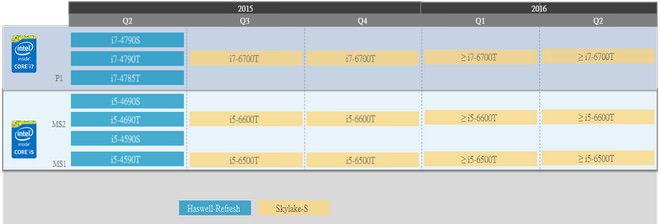
↑ Skylake低電壓版本Core i5/i7 型號處理器i7-6700, i5-6600, i5-6500, i5-6400, i7-6700T, i5-6600T, i5-6400T,將於今年第三季後陸續發佈,時程如圖所敘。
DDR 4 / DDR3L 老少通吃
在記憶體部份,Skylake在內建的記憶體控制器規格亦有改動,原生支援DDR4-2133,同時也向下相容DDR3L-1600。大家要看仔細了,向下相容DDR3L並不完全等於完全相容DDR3,前者工作電壓僅1.35V,而標準DDR 3模組工作電壓則為1.5V。從規格面來看,似乎無法直接與100系列晶片組主機板搭配使用,但其實在Haswell平臺時,跟低電壓版DDR 3模組也不見有相容性上的問題,套在更早的IVB平臺亦是如此。因此筆者猜測,主機板廠應該可以推出部份產品,直接相容標準DDR 3模組,讓某些舊平臺用戶在昇級新一代100系列平臺時,加減省下一些費用。
而目前DDR3L產品比較常在筆電上看到,加上目前DDR4價格相較去年已有不小降幅,若在DDR3L與DDR4之間作選擇得話,或許直上DDR4才是一個相對兼顧性能與價格的首選方案。

↑ DDR3L較常見於筆記型電腦中,無論是電壓或尺寸,都比標準DDR3模組小上一號。
DDR4記憶體 X99初登場
DDR4記憶體對於大多數的使用者或許還相當陌生,推出即將滿週年的X99晶片組則是首次導入DDR4的平臺。相較於DDR3記憶體,DDR4無論在外在或是內在上,都有了更大幅度的演進。首先,DDR3以前的記憶體,金手指都是以平直態在使用者面前呈現,而DDR4在金手指設計上,則略顯彎曲狀。
在防呆缺口上,DDR4比DDR3更加接近中間位置,而在金手指接點數量上,DDR4計有284個,比DDR3的240個多出了44個。而也因此,DDR4每一個接點之間的間距,從1mm縮短至0.85mm。
或許是mini-ITX與大型散熱器的流行,DDR3記憶體金手指是整片平直地埋在DIMM槽內,其接觸面積相較DDR4更大,摩擦力相對DDR3也來得更大。這對於空間有限的mini-ITX機殼或是大型散熱器卡高度的情況下,DDR3記憶體有時在安裝或是拔除上,必需得先將散熱器卸除才能順利進行。
仔細觀察DDR4金手指,可以發現中間部位稍顯突出,邊緣則漸為收矮,在中央的最高點與兩端的最低點之間,則帶以微彎曲線渡過。如此一來,DDR4金手指既能夠與DIMM插槽保有充足的訊號接觸面,在拔除記憶體時,也比DDR3來得更加輕鬆許多。

↑ 上方為DDR4記憶體,下方則為DDR3記憶體,仔細觀察,你會發現DDR4記憶體的金手指並非平直到底,而是中間略凸,兩邊微有彎曲。
Bank Group 分組架構
相信大家對於DDR4最感興趣的,莫過於速度與容量上的提昇。從技術白皮書來看,DDR4每針腳位都可提供每秒256MB/s(2Gbps)傳輸速度,作個簡單換算,DDR4-3200的頻寬高達51.2GB/s,相較於DDR3-1866高出71.5%,更不用說白皮書中表明DDR4頻率可達4266MHz。
我們知道,DDR記憶體在歷代演化的過程中,都採用了所謂的資料預取機制(Prefetch),理所當然DDR4也採用了這項機制。不過,到了DDR4世代,在資料預取上仍沿用DDR3的8n資料預取架構而未有提昇,因此最終DDR4導入了Bank Group分組架構,作為提昇效能的手段之一。
簡單來說,在DDR4的每個Bank Group中,都可以獨立讀寫資料,而Bnak Group可以選擇2個或4個獨立分組,而DDR4模組內的每單位Bnak Group都可獨立進行讀取、寫入、喚醒及更新等動作。從數量來看,如果記憶體內部設計了2個獨立的Bnak Group,那麼資料預取則來到16n;如果使用了4獨立的Bank Group,那麼資料預取則一口氣提高到32n。
換言之,如此一來,資料吞吐量得到了直接有效的提昇,其等效頻率也當然隨之受益匪淺;一言以蔽之,Bnak Group是DDR4提昇頻寬的關鍵技術之一。
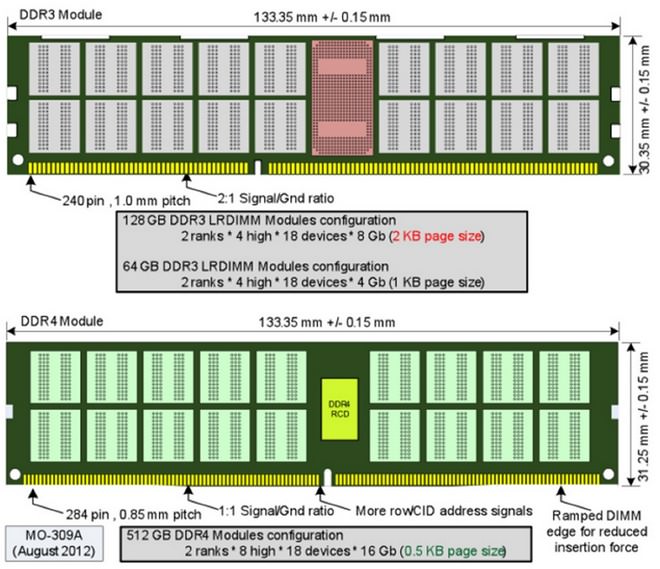
↑ 前後兩代DDR記憶體比一比,其實兩者在高度上就略有差異。此外,PIN腳數量、間距也有所不同,雖然歷代DDR都採用了資料預取機制(Prefetch),但最終DDR4導入了Bank Group分組架構,作為提昇效能的手段之一。
DDR3 多點分支單流架構
我們知道,DDR3採用多點分支單流架構,在同一條通道下,可以掛上許多同樣規格的記憶體晶片。這樣的設計有一個明顯的缺點,那就是一旦當資料傳輸量超過通道最大承載量時,就算記憶體容量提高再多,效能的提昇也是微乎其微。
簡單打個比喻,記憶體容量就好像注水量,只要注水量不超過水管通道傳輸量,那麼只要專注提昇注水量,那麼最後累積的總水量就會得到顯著的提昇;反之,一旦注水量已大於水管傳輸量時,此時再去增加注水量,對於單位時間內的總水量成長幫助不大。
換言之,將記憶體從2GB昇級到4GB,你可以感受到速度變快、效能提昇,那是因為傳輸通道還沒被吃滿,但只要容量往上遞增,在效能增長上的邊際效益將會在達到臨界點時失去動力。總評而論,DDR3的多點分支單流架構,在記憶體容量上的增加很簡單,但很容易受到單條寶貴的傳輸頻寬之限制。
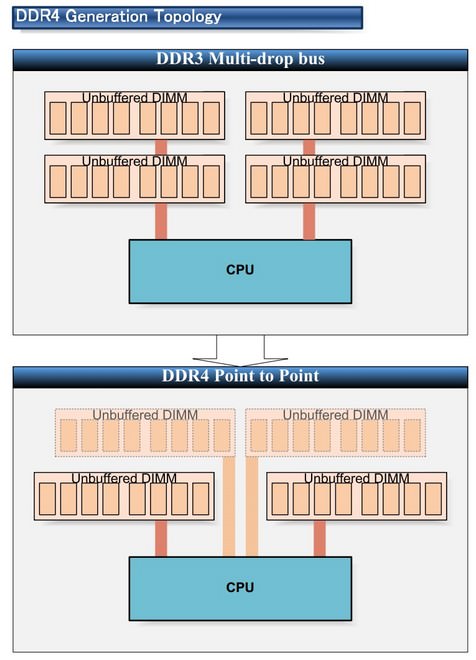
↑ 簡單來說,DDR3採用了大水庫理論,所有資料集中到一根大水管後送出。而DDR4則採用點對點分流架構,當每一條水管流量都很大時,累加起來的流量則會超過單一條大水管,而且還能避免瓶頸效應拖慢整體效能。(圖片來源︰PC Watch)
DDR4 點對點傳輸架構
在新一代DDR4的架構中,傳輸部份採用了點對點設計,也就是每一個晶片控制器對應專屬唯一的通道,也就是說一口出水井只對應一條輸水管,如此一來就不易受到瓶頸效應所帶來的限制,模組設計更加簡化、頻率提昇也更加容易。
但點對點傳輸架構的缺點也相當明顯,因為點對點的每條通道只能對應一根記憶體,如果單條記憶體容量太小,就像單口井的出水量太少,那麼總傳輸量也就是總出水量,甚至有可能比DDR3的多點分支單流架構還要來得少。
解決這個問題的方法既直接又簡單,那就是只要把單條記憶體的容量拉大就好啦!老實說,鍵盤上打字增加容量很簡單,實務上可沒那麼容易,不然現在記憶體早就一條16GB滿街跑了。
行文至此,我們得把因果關係倒過來看,事實上,是晶圓廠的輪班星人們先發展出所謂的3DS(3-Dimensional Stack,3維堆疊)製程,使得單顆晶片的容量增加,最終才能使得整條記憶體模組的容量一舉擴大。也因為有3DS製程,DDR4導入了點對點傳輸架構,在效能提昇上才有了實質意義。


↑ 因為有了3DS堆疊封裝製程,得以讓單條DDR4記憶體容量得以更大,才使得DDR4的點對點傳輸架構變得有意義。
TSV矽穿孔 3DS堆疊封裝
3DS製程最早由美光(Micron Technology)所提出,這是一種堆疊封裝技術,而實作手法又有兩種,一種是單顆晶片在封裝完成後,在PCB上堆疊;另一種則是在晶片封裝之前,在晶片內部進行堆疊。在絕大多數的情況下,只要能夠解決散熱問題,內部堆疊封裝可以一舉大幅降低晶片面積,最大的好處就是對於製成品的小型化有相當大的幫助。
在DDR4中,實現3DS堆疊製程的關鍵推手,則是矽穿孔技術(TSV,Through Silicon Via)。TSV以雷射或蝕刻為手段,在矽晶圓打出一個小洞,然後以導電材質穿過這個小洞後將多個矽晶圓串接起來,此後不同矽晶圓之間的訊號便得以傳輸。
也就是說,透過3DS製程的堆疊封裝,使得單一晶片的發熱量更小、容量更大,因此在DDR4記憶體模組成品上,就可以塞下更多的晶片,單條記憶體容量也隨之更大。

↑ 透過TSV矽穿孔技術,得以將多個矽晶圓串接起來,最終在3DS堆疊封裝製程下,晶片的發熱量更小、容量更大。
低電壓 低功耗
DDR4的另一個亮點,則是能夠以相對DDR3更低的電壓運行系統。事實上,DDR4相較於DDR3,由於時代的進步,製程工藝本來就較為先進,以本次搭配測試的Kingstone DDR4記憶體為例,顆粒採用20nm製程,因此能以1.2V電壓穩定運行系統,相較於DDR3標準工作電壓1.5V,理論上擁有兩成以上的節能效率。
除此之外,DDR4搭載了溫度自更新回饋機制(TCSE,Temperature Compensated Self-Refresh),能夠降低晶片在自動更新時所需耗費的電力,同時,還導入了資料匯流反轉機制(DBI,Data Bus Inversion),使得VDDQ電流量得到有效控制。平心而論,DDR4在功耗上的下降,還是稱得上與時俱進。
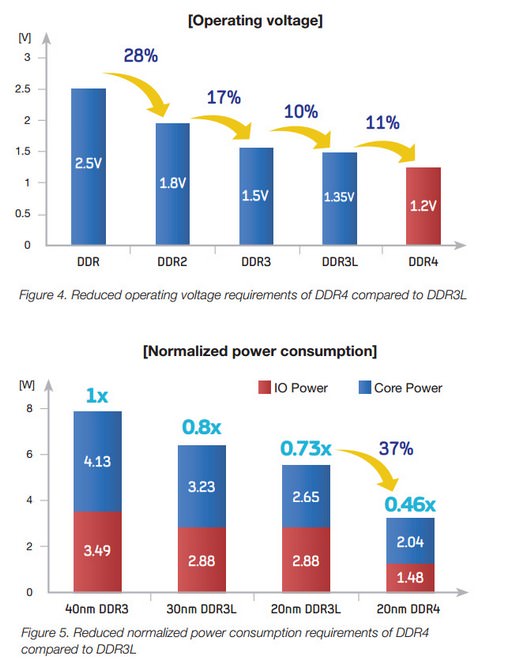
↑ 從圖表中,我們可以看到初代DDR一路演進到DDR4,對於功耗上的表現都有著亮眼的進步。
1151 / 1150 / 1155腳位 老中青比一比
接下來,胖達選用了Core i7-6700K搭配Z170平臺,與前一代Z97+Core i7-4770K及更前一代的Z77+Core i7-3770K進行比較測試;最終用以對照1151腳位、1150腳位及1155腳位平臺之間的效能演進。
我們就處理器規格進行比較。1150腳位、Haswell代表Core i7-4770K與1155腳位、Ivy Bridge代表Core i7-3770K幾乎如出一轍,包括︰同為22奈米製程、四核八緒、預設時脈為3.5GHz,睿頻最高可至3.9GHz,以及同樣擁有8MB L3 Cache。Core i7-4770K與Core i7-3770K最大的不同之處,則在於前者加入了AVX2及FMA3指令集,對於整數、浮點運算的效能表現上,會有所提升。相較之下,最新一代1151腳位、Skylake代表Core i7-6700K採用14奈米製程,四核八緒、預設時脈為4.0GHz,睿頻最高可至4.2GHz、L3 Cache則為8MB,頻率得到了直接的拉昇,對於Core微架構而言,4GHz時脈算是一個不低的頻率。
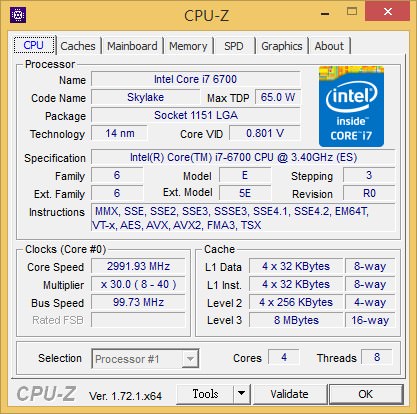
↑ 從CPU-Z中,最新一代1151腳位、Skylake代表Core i7-6700K採用14奈米製程,四核八緒、預設時脈為4.0GHz,睿頻最高可至4.2GHz,TDP為65W。不過這顆是早期工程版,正式量產版規格可能會有所不同。
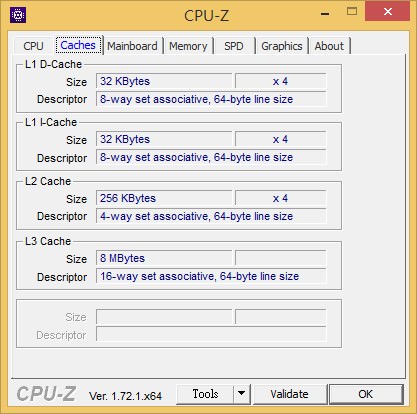
↑ Core i7-6700K之L3 Cache則為8MB,這個部份從Core i7-3770K與Core i7-4770K以來一直沒變。
取消IVR電壓輸入融合
在Haswell時期,英特爾將原本主機板上常見的供電穩壓模組(Volatge Regulator Module,VRM),透過一枚獨立供電晶片,予以整合至Haswell之中,稱之為「電源調節模組」(IVR)。該晶片尺寸約為13×8.14(mm2),具有可程式化特性。內含20個供電單元(Power Cell),其中每個單元都可看成微穩壓器,理論上最高可實現320相供電。
IVR設計可使供電獨立,並精準地控制每一個CPU核心與內嵌的GPU核心,涵括記憶體、PCI-E等;以達節能與效能之間的兩全齊美,因此能夠實現C6 / C7超低功耗待機狀態。然而,此舉使得多家主機板廠在硬體設計上,走向同質化的趨勢;以往數位供電、32相、甚至40相供電都已不再是天大賣點。不過,在這次Skylake平台上,INTEL將FIVR調壓模組從處理器拉回主機板端,供電或許又是板廠可以拿來行銷說嘴的賣點,而正式板處理器是否會改回Ivy Bridge時代的焊錫散熱,也將決定超頻幅度高低。
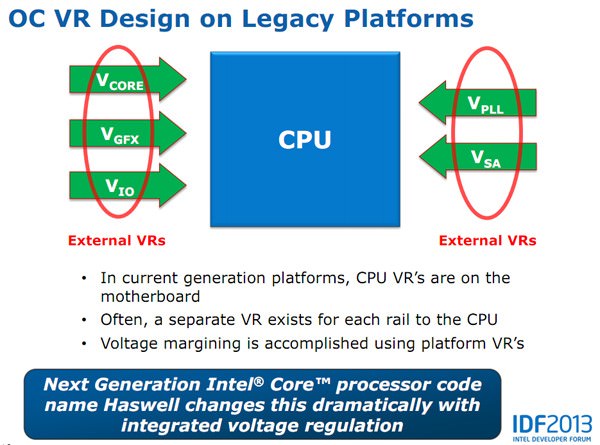
↑ Haswell將傳統主機板上五組電壓輸入,全都整合其中,但這次Skylake又將這五組FIVR拉出來,重新放在主機板上另設模組加以作為供電之用。
每瓦效能 更上一層
經過反覆測試後,Skylake在浮點運算表現上小有進步,記憶體讀寫效能的提昇則是相當驚人,當然這主要也是受惠於DDR4的先天架構與製程更佳所致。
而在於CineBench R11.5的OpenGL項目測試上,Core i7-6700K搭配Z170平臺,相較Z77平臺有了51.94%的領先、相較Z97平臺則有112.48%的領先,對於某些遊戲、軟體及影音轉檔來說,確實算得上是一大福音。
其次,在溫度方面,胖達在室溫攝氏26度下,以英特爾Ivy Bridge原廠空冷散熱器,運行新版3D Mark。透過TES-1326S 紅外線測溫槍,量得Z170平臺處理器為攝氏65.2度,Z97平臺處理器為攝氏68.1度,Z77平臺處理器為攝氏66.7度;透過松大變電家量測功耗,量得Z170平臺功耗為121瓦,量得Z97平臺功耗為141瓦,Z77平臺功耗為129瓦。
由於Skylake為14奈米製程,因此在功耗的降低是可想而知的結果,等到下一次Tick階段的到來,相信在製程、功耗、溫度上,將會有更上一層樓的表現。

↑ 由左至右,分別是Core i7-6700、Core i7-6700K及AMD A10-6800K(哈哈哈~)。

↑ Core i7-6700、Core i7-6700K及AMD A10-6800K背面接點特寫,前兩者為1151腳位,後者為FM2腳位。
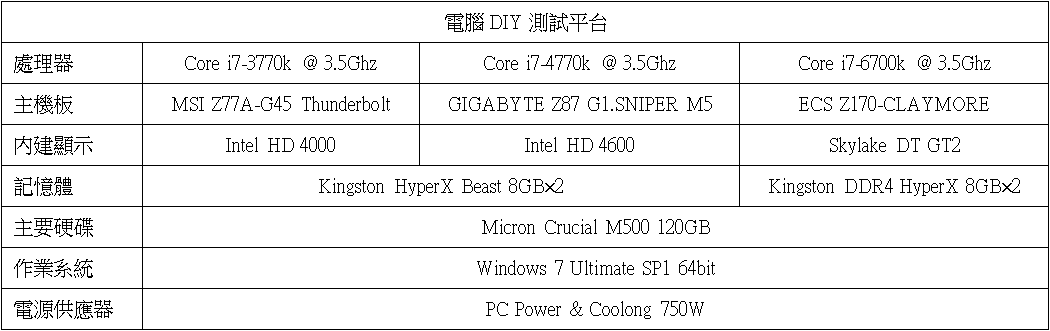
↑ Core i7-6700K在CPUMark 99的測試成績為754分。
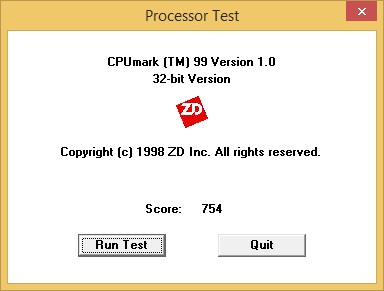
↑ Core i7-6700在7-Zip效能測試下成績一覽,表現不錯。
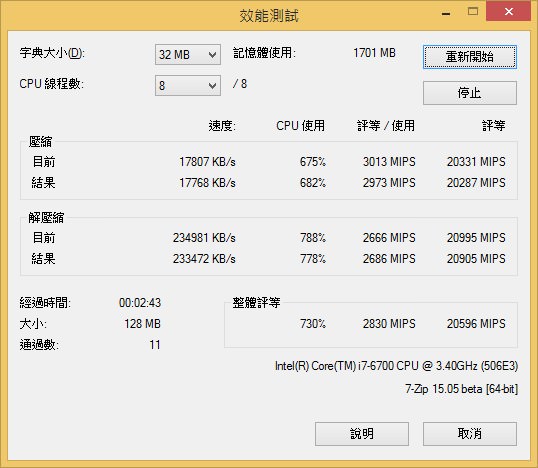
↑ Core i7-6700K在AIDA64記憶體與快取測試成績一覽。
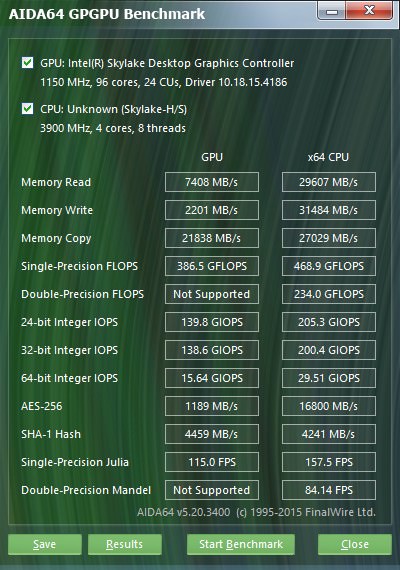
↑ Core i7-6700K在AIDA 64 GPGPU測試,不難發現iGPU表現已非吳下阿蒙,即使在主流級遊戲運行下,亦能取得不錯效果。
H.265硬解 內顯新世代
本次Skylake最大的亮點,應該是在內顯效能的強化上。首先,Skylake的iGPU支援DirectX12、OpenGL 4.3/4.4及OpenCL 2.0。透過DXVAChecker不難發現,其內顯支援 HEVC_VLD_Main 與 HEVC_VLD_Main10,意味能直接解 HEVC / H.265 及VP8 / VP9編碼並進行8/10bit 影片解碼加速。影片輸出解析度最高為4096×2304;當然,3螢幕輸出亦不成問題。
此外,從3DMARK測試來看,分數有著爆炸性的成長,許多遊戲實測後發現,即使在FULL HD解析度下,特效全開也幾乎都能保持在40幀以上。以多款遊戲測試來看,Core i7-6700K的內顯效能已有接近NVIDIA GTX 650的水準,若單純只是想打LOL,其實組一台ITX Skylake迷你機,將會是不錯的選擇。
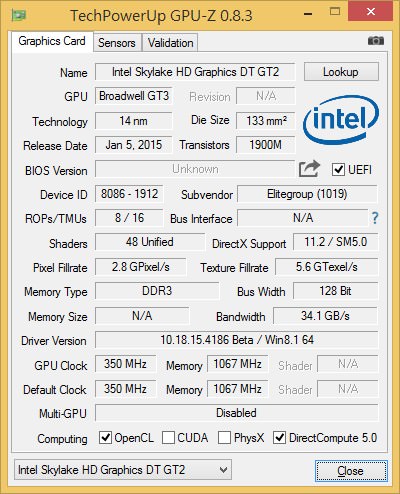
↑ 透過最新版GPU-Z 0.8.3,內顯資訊其實還不太正確,截圖僅供參考。
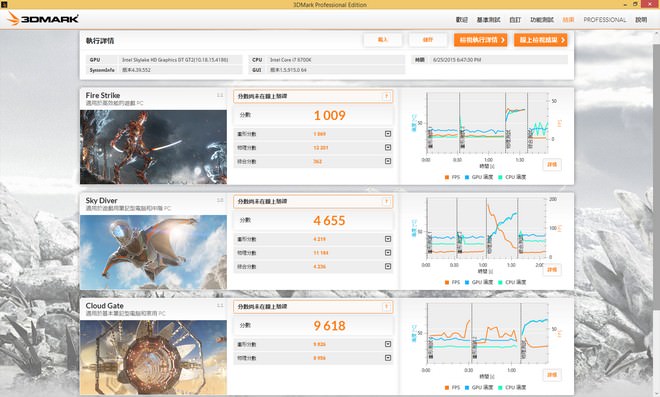
↑ 由新版3D MARK之測試成績,可發現SKYLAKE內顯在效能上接近GTX 650,繪圖效能相當驚人!
Windows 10 × Skylake 尋道圖強
胖達玩了10幾年的處理器,Intel有點像每次考試都拿99分、排名全校第一的模範生,日子久了,似乎大家覺得Intel不只要考第一名,更應該要拿100分;比較殘念的是老搭檔微軟推出的Windows 8,在市場上口碑普遍不佳,Wintel生態系於是乎開始被使用者質疑,Intel可說遭受到池魚之殃。否則MACBOOK也是Intel Inside,銷售量及市場歡迎度一直居高不上、一直保持著高人氣。相較之下,對於ARM在行動裝置上的各種Bug及低落效能,眾人就有比較多的包容。
這次微軟東山再起,推出Windows 10作業系統,單從讓「開始鍵」起死回生就知道確實聽到使用者的心聲了!而且提供一年免費昇級計劃,更是回應了MAC OS X Yosemite免費下載的重大決定。對於Intel來說,Windows 10原生支援DirectX 12是一個很好的表現機會,因此這次在iGPU內顯上著力更深,效能有著飛躍性地表現,從本期專題實測結果不難發現,繪圖效能接近NVIDIA GTX 650水準,而且Windows 10支援不同廠牌之間的顯卡混合交火,當中包括處理器內顯與獨顯之間的混合交火,針對一系列衍生的相關議題,我們已經測出很多有趣的成績,在接下來幾期雜誌內容中會陸續和讀者朋友們一同分享。
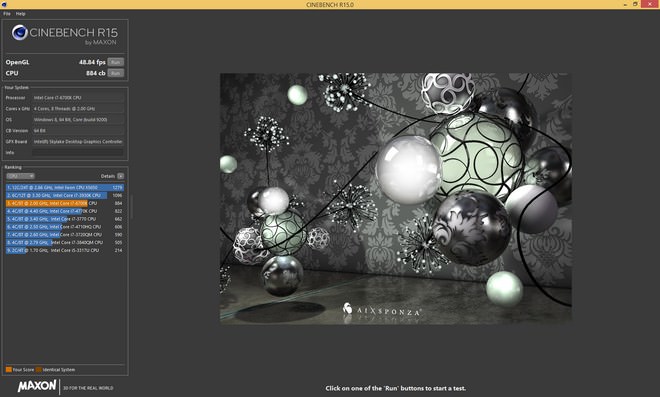
↑ Core i7-6700K在CINEBENCH R15測試下,OpenGL得分高達48.84分,CPU得分也有884的一流表現。
IDF 2015 本月中旬開催
由本次測試結果,我們可以得到一個結論︰單論處理器效能,由於架構、製程的進步,因此運算能力有水準以上的提昇、功耗表現也相當不錯,而此中最大的特色,絕對是內顯效能的大躍進,接近GTX 650的遊戲幀數表現令人耳目一新,對於非重度玩家來說,可以將預算投入鍵鼠週邊,或許可以得到更進一步的遊戲體驗。當然,如果是玩GTA V、巫師 3這類大作,還是建議加裝顯示卡為佳。
最後,胖達本月中旬將遠赴美國舊金山,參加今年IDF英特爾開發者論壇,藉時會在電腦DIY官網帶回INTEL第一手消息,對強悍外星科技感到興趣的朋友們千萬別錯過了!文末,胖達就為讀者介紹本次送測的多張Z170主機板,讓你在首波組建Z170平臺時,也有一個挑選參考的依據喔!
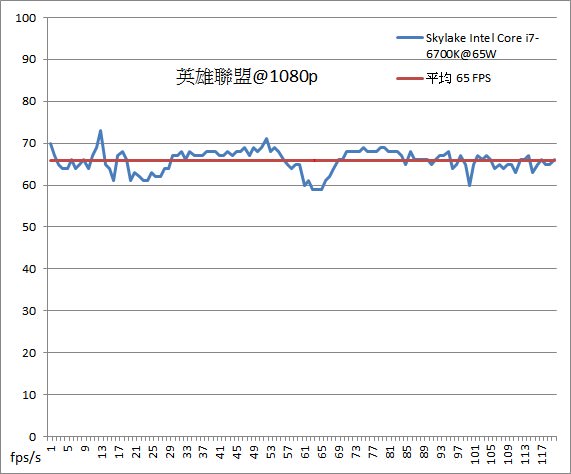
↑ 從目前台灣最熱門的遊戲英雄聯盟實測來看,在1080p Full HD解析度下,Core i7-6700K內顯幾乎能穩定運作在60幀以上,只能說I社的外星科技真不是蓋的!
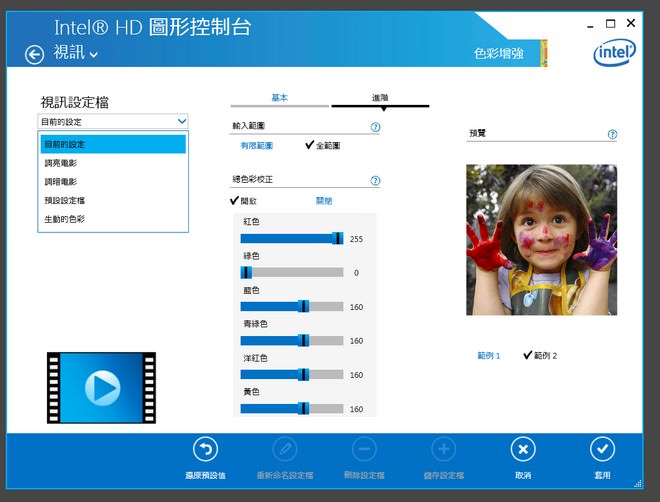
↑ 英特爾iGPU可調整0~255色階範圍,動態範圍不再限制於16~235,可知內顯的進步不只是在量的部份,質的方面亦有所兼顧。
臉書留言