千呼萬喚始出來!NVIDIA GeForce GTX480/470 技術大解密

真正的冠軍現身了!粉碎一切不利的謠言與耳語,GTX480終於出現。毫無疑問效能上一定要完勝競爭對手的高階產品才能帶給企盼已久的玩家真正的感動。而且不要忘記,GTX480還只是單GPU的顯卡!
甚至有人說GTX480才是真正的DirectX11顯卡,到底其中的眉角在哪?還用問!接下去看就知道了。
DirectX 11技術大躍進
相較前一代DirectX10, DirectX11的技術細節確實有了比較顯著的改變。例如MultiThreading、Tessellation和Computer Shader。MultiThreading是將DirectX指令序平行多工化(以往最明顯的就是遊戲儲存一定要暫停,不然畫面一定會停頓!),現在DirectX11則是能夠讓玩家完全感受不到自動儲存與過場景時的停頓,因為現在這兩個執行的指令將不會再單獨的佔用CPU的單一核心,真正解放了多核心CPU的效能。不過這個部份與我們即將要談的內容較無關。與顯卡特效表現有關的還是後兩者的Tessellation和Computer Shader。

圖 / 完全針對DirectX11所設計的硬體架構,讓各種場景、紋理和光影更加逼真。
我們先從Tessellation談起,借由DX11遊戲與AMD的大力宣傳,許多玩家都知道Tessellation的好處,就是能在不增加GPU負擔的情況下,有效率的產生複雜多邊形。雖說看起來Tessellation原理很簡單,但實做起來其實非常複雜。首先必須設定載入低度多邊形模型,並在Hull Shader端設定好控制點,接著交給tessellator去擴增頂點或曲面(但是到這邊都還沒開始貼圖),最後丟給Domain Shader轉化為畫面上的頂點,後續的流程就一如DX10交給Geometry shader 與raster Engine去後製!
Fermi效能優勢的來源:16個Tessellator
NVIDIA這回全新Fermi架構替DirectX11帶來革命性的效能,如同剛才提到Tessellation是DirectX11的靈魂,為了強化這個部份的效能表現,這回NVIDIA的旗艦款GTX480光Tessellator的數量高達16個之譜,將前面提到的三個階段做了微幅調整並命名為Polymorph引擎。以往就算是真的實現了此種做法也都只是線性,過程是不可逆且無法中止,新的Polymorph引擎能讓全部的過程都能達到真正多工平行化處理,這樣一來效能就會跑出明顯差距。
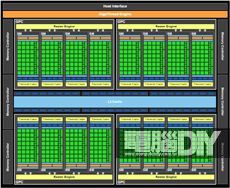
圖 / 從Fermi的架構圖可以看到同時具有16個Tessellator

圖 / Tessellator能大量產生複雜多邊形,大幅提升原本3D繪圖的細膩度。
因此在微軟DX11 SDK最嚴格的環境下測試,GTX480的效能能夠獲得極大化的發揮,Polymorph引擎可說居功厥偉。除此之外,Fermi這次在後端Raster Engine也做了不少改進。在Polymorph引擎運算完後,接下來工作就會被交給NVIDIA Raster引擎繼續分成三大工作階段處理。
後端引擎優化提升效能
第一個階段Edge Setup計算所有從Polymorph引擎送來顯示空間的頂點與三角形信息,計算並移除所有超出顯示邊界,以及非正面朝向視點的三角形信息;在第二階段則由Resterizer進行圖像的光柵化, 進行光柵內平均顏色計算,這回NVIDIA GeForce GTX 480/470獨家的演算優化,整體運算能力可以達到前所未見的32倍反鋸齒(Anti-Alaising);接著來到第三個階段,Z-Cull將已經完成的光柵化圖像進行Z軸壓縮以加快顯示效率。雖說大家都知道大量堆疊流處理器數量可以有效的增強效能,只是這種作法並沒有辦法發揮DX11的特色(如:Tessellation),更不要提與GPGPU有極大關聯的Computing Shader。


圖 / 全新的後端引擎能夠讓畫面的光影、景深和反鋸齒更擬真。
大幅成長的物理及光影動態運算能力
物理上的呈現與光影效果同樣可以看到GTX480有著革命性的成長。若以上一代卡王GTX285來看,新一代Fermi架構的GTX480/470,不論物理效能或最新的光線追蹤技術,全部都有高達三倍的成長。先讓我們來談物理的部分,PhysX引擎自從被NV收購後開始大量普及在各類型的遊戲上,像去年大賣的蝙蝠俠:小丑大逃亡(Batman:Arkham Asylum)就利用大量的PhysX引擎來產生大量特效(像是煙霧、布幕以及碎片物件)來塑造獨特逼真的場景;卡普空(CAPCOM)推出的暗黑虛空(DARK VOID)更是將畫面的華麗延伸到極致,不只飛行中的碰撞與爆炸火花四射,連敵人被擊中後分解為原子的特效,全部是透過PhysX物理引擎所做出來的。

圖 / 大量極其真實的爆炸四射的火花和光線都是透過物理加速引擎去實現
若是拿GTX480來跑遊戲的話,光場景的物件就能在維持同等流暢的速度下,增加多達三倍的物件,這就是PhysX與其他物理引擎最大的差別。一般物理引擎最多只能在畫面上同時運行、計算5000個物件的互動與碰撞。而新一代GTX480與附贈的SUPERSONIC SLEG DEMO我們就可以看到100萬個物件爆炸互動的場景,每一次爆炸的畫面與效果更是完全不同以往!
Ray Tracing:GPU的一小步,電腦的一大步
再來要提到的是光跡追蹤(Ray Tracing)的部分。這是一個新的科技,不過在專門的領域上已經是行之有年。舉個例子來說,電影工業的阿凡達只利用了37個真人演員,卻可以模擬出數以萬計的腳色與場景,靠的就是無數電腦動畫與後製。

圖 / Ray Tracing能夠真實模擬出現場光源反射,並隨著場景轉換發揮即時動態效果。
而阿凡達採用「PantaRay」光線追踪引擎,可以用來加速遮蓋場景及基於圖像的動態光照預先計算,讓所有人物都能像真正活在潘朵拉行星上。另一個應用則是來自商業領域,如同所有顏色都需透過光線反射人眼才能辨別顏色,而光跡追蹤就是利用GPU去模擬光線的反射直到消失。這又是一個聽起來簡單實做起來卻很困難的部分。當然除了電影外,例如高階影片後製等都需要光跡追蹤運算的協助!
流處理器群完整發揮多工效率
最後我們要提到的是整個GTX480效能提昇的部份。流處理器的增加與HDR光柵引擎的改良最直接的好處,就是整體性能得到提升,以及反鋸齒效能損耗降低。這次GTX480基本上8xAA反鋸齒根本可說是免費奉送。每一個SM(Streaming Multiprocessor)流處理器群架構下都有32個流處理器(這次改名叫做CUDA CORE),比起以往GT200架構多了4倍流處理器數量,也因此每個流處理器群動用了雙分支任務排程器(Dual Warp scheduler)去分配多工任務,同時為了確保每一個CUDA CORE都是在滿載狀況的最佳效率,在最外層記憶體控制器相同階層中,另外再分配了一個大的任務排程器,稱為Giga Thread。由此來確保所有任務分支與排程器能在最有效率下發揮滿載,避免勞逸不均的狀況發生!

圖 / Fermi架構下每一個SM流處理器群下分別有32個CUDA CORE
決戰DirectX就看Fermi
最後行文到此我們也要下個結論,以DIRECTX11的架構來說Fermi真的是有其獨特與優越處,相比較前一代的自家產品不只是每個流處理器效能比之前翻倍,更可怕的是多邊形性能更是提升了多達8倍之多!流處理器效能從GeForce5800以來每個Shader提升了150倍。那猜猜看對手多邊形的效能提升了多少,只有三倍!由此我們可知道這次Fermi完全就是以卡王之姿來迎接眾家對手的挑戰!!
臉書留言